

Ahogy a címben is látható, most az ének felvételekről lesz szó -ez az ami a legtöbb fejtörést okozza az érdeklődőknek-, de mivel nem csak az emberi hang rendelkezik rendkívül széles dinamikatartománnyal, hanem többek között pl. a dobok és pengetős hangszerek is, természetesen az itt ismertetett technikák bármilyen más hangra, hangszerre is érvényesek!
Az emberi hangot minden nap halljuk, jól ismerjük, ezért hamar érzékeljük ha valami nincs rendben vele. Érdemes tehát az énekkel sokat foglalkozni, a lehető legtökéletesebbé tenni, de ne gondoljuk azt, hogy egy jó éneksáv rossz kísérettel jó mixet fog adni! Nekem az a véleményem, hogy nem igaz az, hogy az ének a legfontosabb sáv egy műben (egyforma fontos mindegyik), viszont az igaz, hogy ha valamelyik sávot előnyben kell részesíteni egy másikkal szemben, akkor a legtöbben -mint ahogy én is- az éneket helyezik előtérbe. Minden sávnak meg kell találni a helyét a mixben, ha az ének kilóg belőle, ugyan olyan rossz, mintha egy másik tenné ugyanezt.

Egy felvételen szinte mindig találhatóak zavaró hangerő különbségek. Ez lehet egy-egy halkabbra sikeredett szó, vagy szótag, de akár csak egy betű is, ami miatt jelentősen csökken a szövegérthetőség. A professzionális -és ezáltal a legjobb- megoldás az, ha ezeket a fader automatizálásával szüntetjük meg. Ez adja a leginkább észrevehetetlen és pontos eredményt, mivel ilyenkor leginkább csak magát a hangerőt változtatjuk meg, nem a hangzást. Mi magunk döntünk minden egyes hang, ének esetében sor, szó, szótag vagy betű (hang) hangerejéről. Tudom, hogy ez időigényes és sokszor unalmas feladat, de sajnos ez ezzel jár. Egy másik lehetséges felhasználás, ha az automatizációval érdekesebbé, kellemesebbé, érzelem-dúsabbá varázsoljuk az előadást, pl. egy sor végi hang erősítésével, vagy éppen halkításával.
Rider pluginek
Léteznek úgynevezett "rider" pluginek, amik az automatizációt helyettünk, automatikusan írják be a DAW-ba, vagy teszik meg valós időben (real time). Ilyen pl. a Waves Audio - Vocal Rider és Bass Rider. Mivel azonban ezek is egy algoritmus alapján dolgoznak, nem garantált a 100%-os eredmény. Egy kezdeti, vagy kiinduló állapotnak persze tökéletesen megfelel amit előállít, de ezt később -főleg a bonyolultabb, problémás felvételek esetében- mindenképpen érdemes kézzel korrigálnunk.
Természetesen létezik ingyenes rider plugin is, mégpedig a Terry West - VOCRIDER., illetve a Steady Pro Bundle. Bevallom, én ezeket még nem próbáltam ki, így a működőképességükről egyelőre nem tudok nyilatkozni, de ezt a későbbiekben pótolni fogom. Ismert továbbá olyan technika is, amiben a Vocal Rider plugin működését más pluginek segítségével valósítjuk meg. Erről egy későbbi részben olvashatunk majd.
A fader automatizáció természetesen csak felvétel esetében valósítható meg, az élő műsoroknál nincs lehetőségünk minden egyes sávot kézzel állítgatni, ilyenkor az egyetlen lehetséges megoldás a kompresszor használata.
Dinamika problémák az ének-felvételekben
Dinamika problémák az ének-felvételekben
Egy professzionális, képzett és gyakorlott énekes képes olyan technikával énekelni, hogy csakis akkor változzon a hangereje, ha ezt Ő szeretné. A tökéletes felvételhez kell még egy jó akusztikájú felvevő helység, valamint megfelelő minőségű mikrofon és előerősítő. Ha mindez rendelkezésre áll, a keveréskor akkor is a mixhez kell igazítanunk az énekfelvételünk dinamikatartományát, de koránt sem olyan mértékben, mint egy kevésbé profi felvétel esetében. "Szerencsére" a következő példákban általuk használt Golden Rust éneksávunk nem ilyen, nem tökéletes, bőven találunk majd benne problémát amin gyakorolhatunk!
 |
| Golden Rust-Álom kompresszálatlan éneksáv |
Ez a felvétel jól reprezentálja egy éneksáv széles dinamikatartományát, kb. -15 és +2dBVU közötti kivezérlés értékekkel rendelkezik (0VU=-18dBFS), szemmel is jól láthatóak a kiemelkedő jelszintek, valamint hallható is a különböző hangerejű éneklés.
 Mivel ezt a felvételt én készítettem, tudom, hogy a mikrofon jele minimális analóg kompresszión és limitáláson keresztül került rögzítésre, de ez csak és kizárólag az AD átalakításkor esetleg fellépő nemkívánatos túlvezérlés elkerülése érdekében történt!
Mivel ezt a felvételt én készítettem, tudom, hogy a mikrofon jele minimális analóg kompresszión és limitáláson keresztül került rögzítésre, de ez csak és kizárólag az AD átalakításkor esetleg fellépő nemkívánatos túlvezérlés elkerülése érdekében történt!A mai részben lévő technikák elsajátításához és a gyakorláshoz a Golden Rust zenekar "Álom" című szerzeményéből fogjuk az éneksáv egy részét használni. A jogtulajdonos (Copyright Magyar Zoltán, Minden jog fenntartva!), a felvétel felhasználását csak oktatási célra engedélyezi, kizárólag a Microchips Sound Studio oldal olvasóinak, kizárólag az itt található technikák gyakorlására! Minden más, részben vagy egészben történő felhasználás és további megosztás tilos! A linkre kattintva a letöltő elfogadja a felhasználás fenti feltételeit! (Letöltéshez katt a narancssárga sorra!)

Ha Reaper DAW-t használunk, akkor mindig csak az utolsó helyre tudunk újabb insert effektet hozzáadni, ezért a VU metert minden esetben kézzel kell az utolsó helyre húzni!
Mit szeretnénk elérni?
Mint azt már az előző részben is megtanulhattuk, mielőtt egy felvételen beavatkozást végzünk, határozzuk el mi is a célunk vele. Ez esetünkben azt gondolom teljesen egyértelmű, szeretnénk, ha a nagy dinamikatartomány csökkenne, egyenletesebb, kiegyensúlyozottabb éneket kapnánk, ami jobban belesimul a zenébe. Mindezt úgy szeretnénk elérni, hogy ne egy kivasalt, élettelen valamit halljunk, vagyis tartsunk azért meg egy egészséges dinamikát.
Természetesen szinte bármelyik kompresszort használhatjuk éneksávunk hangerejének kiegyenlítésére, de léteznek olyan készülékek, amik egy kicsit jobban beváltak, vagy egyszerűbben használhatóak erre a célra. Kompresszort mindig az adott feladathoz választunk, de akadnak jól bevált kompresszorok, minek keresgessünk hát? A leginkább ismert és használt klasszikus ének kompresszorok a dbx 160, Urei 1176, és a Teletronix (Universal Audio) LA-2A.
Elektroncsöves kompresszor
Az LA-2A a klasszikus szintező erősítő, ami inkább a hangerők kiegyensúlyozásáért felel, nem pedig a hangzásért, tehát most erre van szükségünk. Persze nem csak énekre, de szinte bármilyen hangszerre jól használható. Ahogy az első részben már megtanultuk az LA-2A egy opto-elektronikus detektorral rendelkező kompresszor. Természetesen az opto kompresszorokat is ki fogjuk próbálni, de mint a sorozat előző részeiben, most is az egyszerűbbtől haladunk a bonyolultabbak felé, ezért nem az opto-elektronikussal, hanem egy az LA-2A-hoz külsőleg nagyon hasonló, változó feszültségerősítésű csöves (variable mu) típusú Klanghelm MJUC Jr. ingyenes pluginnel fogjuk kezdeni a kísérletezést.
 |
| Klanghelm - MJUC Jr. |
Helyezzünk hát el az ének sávunk első insert pontjára egy MJUC Jr-t, és kezdjük meg a beállítást! Ahogy elhatároztuk, a célunk hogy az éneksávunkat a lehető leginkább egyenlő hangerőre hozzuk. Ezt kompresszorral legkönnyebben úgy tehetjük meg, ha a hangos részeket lehalkítjuk a halk részek hangerejére, majd az így kapott jelszintet visszaemeljük a szükséges értékre. Ez célszerűen az énekünk átlag hangereje lesz.

A Sleepy-Time VU meteren láthatjuk, hogy az eredeti dinamikához képest nem sokat csökkentettünk, a mutató még mindig elég nagy mértékben kileng kb. -12 és +2dBVU között. Bár valóban hallani némi kiegyenlítést, de ez koránt sem olyan mértékű, mint azt szeretnénk. Az alacsony jelszint csökkentést láthatjuk a GR méteren is, ami nem nagyon megy -2dB fölé. Ez még nem is lenne olyan nagy gond, de sokszor bizony túl hosszúnak tűnik az alkalmazott Release. Ezt hallhatjuk pl. az "és elrepült, az ÁLMUNK" résznél, ahol az "álmunk" szó hallhatóan lehalkul. Jól hallható a zavaró hatás a "két tűz között MERRE MENJEK ÉN" résznél is. Nincs tehát értelme a kompressziót tovább növelni, hátha azzal jobban kiegyenlíthetjük a hangerő különbségeket, itt bizony az időállandókat kell elsőként rendbe hozni.

Végtelenítsük ismét az első 2 ütemet, hogy újból elvégezhessük a beállítást. Ez kb. 14,6 Compress értéknek felel meg. Hallgassuk meg a teljes fájlt ezzel a beállítással! Hát nem vagyok elájulva, alig van valami kompresszió, max -2dB. A gyors Attack és Release érték miatt már a kezdeti, alacsonyabb jelszintek is jelszint csökkentést generálnak, ezért ezzel a kompresszorral sajnos nem tudjuk azt megoldani, hogy az első két ütemben ne legyen kompresszió, csak a többiben, ott viszont megfelelő -sokkal nagyobb- mértékű. A szintező erősítő működése egyébként pont erről szól, mindig van valamennyi jelszint csökkentés. Igazából a végeredmény számít, nem a szabályok betartása, válasszunk tehát most egy másik utat a célunk eléréséhez, és állítsuk be úgy a kompresszort, hogy a lehető legkiegyensúlyozottabb legyen a sávunk kimeneti jelszintje.
Az előző részben már megtanultuk, hogy egyéni sávok esetében az észrevehetetlen kompresszióhoz az ajánlott jelszint csökkentés kb. 3dB. Állítsuk tehát most be úgy a kompresszió mértékét, hogy a műszeren ezt az értéket olvassuk le. Ez nálam a hangos részeknél 18,3-as Compress-nél következik be. Az ennél sokkal magasabb értékeknek nincs sok értelmük, hiszen azokon a GR műszer nem tér vissza a nulla értékre, vagyis a kompresszor mindig halkít a jelen, nem történik valódi jelszint követés (gain rideing), nagyrészt csak egy hangerő potméterként üzemel. Ez a kompresszor tehát ennyit tud... vagy mégsem?
 |
| MJUC Jr. végső beállítása és az általa előállított kompresszált fájl képe. |
Kapcsoljuk az időállandókat "AUTO", azaz automata módba! Máris sokkal jobb a hangzás, és magasabb jelszint csökkentést is kapunk a hangos részeken (akár -6dB), kevesebbet a halkabbakon. A detektor jól követi a jelszint változást. A hangzás a FAST (gyors) álláshoz viszonyítva kissé fojtottabb, puhább, viszont sokkal kiegyensúlyozottabb. A műszerünk is jobban követi a ritmikát. Hasonlítsuk hát össze az eredeti és a kompresszált hangunkat! Helyezzük bypass állásba a plugint. Ezt megtehetjük a kompresszor kivezérlésmérőjére, vagy a világító POWER lámpára kattintva is. (Ha ezt a módszert választjuk, egy kattanás nélküli bypass funkciót használhatunk, ami valljuk be, nem rossz dolog!) Mivel eddig nem végeztük el a jelszint kezelést (gain staging), ezért nem meglepő módon a kompresszor által lehalkított jelszint bizony halkabb, mint az eredeti (van aki mást várt???). Kompenzáljuk a veszteséget a Make-up-al, én 5dB-t találtam jónak.
Nagyjából elértük a célunkat, az éneksávunk kiegyensúlyozottabb, dúsabb és teltebb lett, sokkal profibban, lemezszerűbben szól. Az MJUC-nak köszönhetően a dinamika tartományt sikerült -15 és -1dBVU közé szorítanunk. Ez talán még mindig túl sok, de egy nagyon dinamikus, élő, eredeti és kiegyensúlyozott előadást kapunk vele. A mellékelt képen láthatjuk is, hogy milyen szépen egy szintre kerültek a nyers wav-ben még kiemelkedő jelcsúcsok, az egész sokkal egységesebb képet mutat. Ezt nagyon is hallhatjuk, ha párszor végighallgatjuk a sávot ki és bekapcsolt kompresszorral is! Természetesen tovább finomíthatjuk a beállításokat, de sokkal jobb eredményt az MJUC Jr-tól már ne várjuk. A hangerők nagyjából kiegyenlítettek, a dinamika is megmaradt, amit jól láthatunk a Sleepy VU meter mozgásán is. Ez nem egy helyben áll, hanem szépen követi az ének ritmusát, de mégsem olyan kilengésekkel és élesen, mint kompresszor nélkül. Bár a csöves kompresszorok -mint ez is-, nem a gyorsaságukról híresek, mégis azt kell hogy mondjam, jól teljesített! Ez egy nagyon jó kompresszor plugin!
Opto-elektronikus kompresszor
A csöves kompresszorunk után most próbáljunk ki egy vérbeli ének szintező erősítőt (Leveling Amplifier, röviden: LA), vagyis egy opto-elektronikusat. Használhatnánk persze az előző részben már megismert Antress - The Lost Angel-t is, de ismerkedjünk meg most inkább egy másik ingyenes darabbal, ami közel 90%-ban képes utánozni egy Waves CLA-2A plugint. Ez pedig nem más, mint a Variety of Sound - ThrillseekerLA kompresszora, ami egy analóg működést emuláló, opto-elektronikus, külön kapcsolható harmonikus torzítással ellátott szintező erősítő. Ennek köszönhetően részben képes utánozni az eredeti LA-2A transzformátora és elektroncsöves erősítője által tovább finomított, "lekerekített élű" hangzást is, ami rendkívül népszerűvé tette az eredeti kompresszort többek között az éneksávokon is.
Az opto-elektronikus detektor sajátossága, hogy automatikusan alkalmazkodik a beérkező hanganyaghoz, és a fény fizikai tulajdonságaiból adódóan "intelligensen" követi a jelszint változást (auto release és auto ratio). Ez nagyon jól jön olyan hanganyagok esetében, mint pl. a basszus és az ének, ahol nagy, de rövid idejű, és kicsi, hosszú idejű hangerő különbségek váltakozva jönnek létre.

Kapcsoljuk hát ki az MJUC-t és a következő insert pontra helyezzük el a ThrillseekerLA-t. (Ne feledjük a Sleepy Mono Channelt utána helyezni!) Mivel ezen a kompresszoron az általános paraméterek mind megtalálhatóak, a beállítást végezzük most az előző részben megismert 5 lépéses módszer szerint.
Az első lépés a kompresszor alaphelyzetbe állítása. Mivel ez a plugin nem jelzi az aktuális értékeket, így a beállításokat a mellékelt képekről kell majd lemásolni. Fentebb látható az első, a kezdeti értékekkel. Ahogy a nagykönyvben meg van írva, Input 0dB, Attack és Release a lehető legkisebb, Range (ez gyakorlatilag a Ratio-nak felel meg) maximumon, Output 0dB.
 A VOS (Variety of Sound) pluginekre jellemző, hogy kettő, vagy több referencia szinten képesek működni. Ez azért van, mert sokan használják masztering feladatokra, ahol a jelszinteknek 0dBFS-hez közelinek kell lenniük -hiszen pontosan ez a masztering lényege. Keveréskor viszont inkább a -18dBFS az elfogadott (vagy a -20, esetleg a K-system). Mivel mi most nem maszterelünk, hanem "keverünk", ezért a Mix-level-t állítsuk -18dB-re, mert az énekfelvételt is -18dBFS (-23dBLUFS) referencia szintre állítottam be. Az SC (side chain) Filtert és a külső Sidechaint (SC Route) most ne kapcsoljuk be! A kivezérlés mérőt állítsuk "GR" állásba, így a létrejövő jelszint csökkentést fogja mutatni. A szaturációt az Interstage kapcsolóval indíthatjuk el, de egyenlőre ezt is hagyjuk kikapcsolva.
A VOS (Variety of Sound) pluginekre jellemző, hogy kettő, vagy több referencia szinten képesek működni. Ez azért van, mert sokan használják masztering feladatokra, ahol a jelszinteknek 0dBFS-hez közelinek kell lenniük -hiszen pontosan ez a masztering lényege. Keveréskor viszont inkább a -18dBFS az elfogadott (vagy a -20, esetleg a K-system). Mivel mi most nem maszterelünk, hanem "keverünk", ezért a Mix-level-t állítsuk -18dB-re, mert az énekfelvételt is -18dBFS (-23dBLUFS) referencia szintre állítottam be. Az SC (side chain) Filtert és a külső Sidechaint (SC Route) most ne kapcsoljuk be! A kivezérlés mérőt állítsuk "GR" állásba, így a létrejövő jelszint csökkentést fogja mutatni. A szaturációt az Interstage kapcsolóval indíthatjuk el, de egyenlőre ezt is hagyjuk kikapcsolva.
Második lépés a Threshold beállítása, igen ám, de itt nincs ilyen. Vagyis nem látjuk sehol sem. Valójában ez a kompresszor rögzített küszöbértékkel dolgozik, és az Input potival tudjuk a beérkező jelet ehhez növelni, vagy csökkenteni. Indítsuk el a lejátszást, és nézzük, mi történik a 0dB-es értéken!
Már a sáv leghalkabb részén is -3dB GR-t jelez a műszerünk, a legmagasabb érték pedig -10dB. A hangja végülis nem rossz, akár meg is felelhetne, ha nem tudnánk hogy a folyamatos -3dB jelszint csökkentésnek nem sok értelme van. Mit tehetünk? Kövessük az eddigi módszerünket, vagyis próbáljuk meg elérni, hogy a halk részeken ne történjen jelszint csökkentés. Ehhez a küszöbértéket kell növelni, azaz halkítsuk le a bemenő jelet az Input-al egészen addig, amíg a leghalkabb részeken már nem lesz GR. Ez kb. 10 óra állásban következik be. Mint hallhatjuk, a halkítással a kimenő jelszint is csökkent, de ezt az Output potival tudjuk kompenzálni. Én nagyjából 2 óra állásnál megfelelőnek találom. Hallgassuk most végig a sávot, hogy mit tesz vele a ThrillseekerLA. Hát nem sokat, a maximális GR -1dB körüli, a Sleepy VU szinte ugyan úgy kileng, mint a kompresszálatlan hang esetében. Ez bizony nem lesz jó megoldás, ismét oda érkeztünk, ahová az MJUC esetében.
 Folytassuk tehát a beállítást egy másik módszerrel, vagyis a hangos részekhez állítjuk az Input-ot, mégpedig úgy, hogy első próbálkozásra az ajánlott kb. -3dB GR keletkezzen.
Folytassuk tehát a beállítást egy másik módszerrel, vagyis a hangos részekhez állítjuk az Input-ot, mégpedig úgy, hogy első próbálkozásra az ajánlott kb. -3dB GR keletkezzen.
Ehhez loopoljuk be a legnagyobb dinamikával rendelkező szakaszt, mégpedig 9.1.0-tól 13.1.0-ig (13.241-19.862sec), biztos ami biztos, halkítsuk le a kimenetet az Output-al mondjuk az alap 0dB-re és indítsuk el a lejátszást. Növeljük az Input-ot addig, amíg a kívánt GR-t el nem érjük. Ez kb. 11 óra körüli állásnál valósul meg. Hallgassuk meg a teljes sávot, és figyeljük a Sleepy VU-t! Még mindig elég nagy a különbség a halk és hangos részek között -10 és -2dB között ingadozik. Sajnos a kompressziós arányt már nem tudjuk tovább növelni, hiszen az maximumon van (Range 100), tehát nem tehetünk mást, mint az Inputot tovább növeljük, mondjuk -6dB GR környékére. Ez bizony a 0dB Input-al lesz a legjobb... Bizony, van amikor az ember téved, de ez nem probléma! A lényeg, hogy a végeredmény jó legyen, ezért ha nem vagyunk biztosak a dolgunkban, inkább próbáljunk ki több lehetőséget is! A 0dB Input-al a leghangosabb résznél -7dB fölé is felmegy a jelszint csökkentés, de semmi baj, jöjjön a következő pont az 5-ből.
Harmadik lépés: Attack beállítása. Ismét jelentkezik az MJUC-nál már tapasztalt pumpáló hatás a "két tűz között MERRE MENJEK ÉN" résznél. Mint ott, itt is az időállandókat kell kezelésbe vennünk. Mivel mi most a lehető leggyorsabb beállításon vagyunk, ezért itt nem működik a még gyorsabbra kapcsolás, de nem is kell! Ha figyelmesek voltunk, már minden bizonnyal észrevettük, hogy az Attack legkisebb értéke 0 ms. Ez bizony túl alacsony érték, a kompresszor ezért nem tud szinte soha visszatérni az alap 0dB GR állapotába. Kezdjük hát ezt növelni, és figyeljük a hatást! Természetesen a problémás részt végtelenítve végezzük a beállítást, 9.1.0 és 13.1.0 között. Ahogy növeljük az Attack értékét, úgy lesz egyre tisztább, nyitottabb a hangzás, és ezzel együtt csökken a GR, valamint a zavaró lehalkulás is. Talán a 7-ik vonásnál a legjobb a beállítás. (lásd a lenti képen)
Ha az értékét visszaszámoljuk a 9-ik vonás 13ms értékéből, akkor kb. 10ms-ot kapunk, ami pont megegyezik az eredeti LA-2A attack idejével, sőt az előző részben ajánlott, legkevésbé észrevehető kompresszióhoz szükséges értékkel is. (Ne feledkezzünk el a jelszint kezelésről, és minden beállítás után korrigáljuk a kimenő jelszintet az eredeti szinthez!)
 Negyedik lépés: Release beállítása. Ha a fenti értékekkel végighallgatjuk a teljes sávot, még mindig hallhatunk és a VU meteren láthatunk túlzott dinamikatartományt. Néhány erőteljesebb hang szinte zavaróan kiugrik a többi közül. Ennek megoldására növeljük meg a Release idejét. Ilyenkor a kompresszor lassabban tér vissza az alapállapotába, vagyis hosszabban tartja a jelszint csökkentést, és ezáltal jobban kisimulnak a különbségek. Amikor elkezdjük emelni az értéket, azt tapasztalhatjuk, hogy a hangerő csökkenni kezd, vagyis gyakorlatilag egy lehalkítást hajtunk végre. A feladatunk most az, hogy megtaláljuk azt az ideális értéket, amikor már elegendő hangerő csökkentés történik, de még nem túl hosszan, így megtartva az eredeti dinamikát. Ha túl nagy értéket választunk, akkor nem történik valódi jelszint követés, ha túl alacsonyat, akkor nagy marad a különbség a hangos és halk részek között. Erre legjobb példa az Attack beállításánál is említett "két tűz között MERRE MENJEK ÉN" rész. Számomra a második vonással megegyező érték adja a legkiegyensúlyozottabb hangzást. (lásd a fenti képen) Persze ez ízléstől is függ, másoknak lehet hogy más Attack és Release beállítás tetszik jobban.
Negyedik lépés: Release beállítása. Ha a fenti értékekkel végighallgatjuk a teljes sávot, még mindig hallhatunk és a VU meteren láthatunk túlzott dinamikatartományt. Néhány erőteljesebb hang szinte zavaróan kiugrik a többi közül. Ennek megoldására növeljük meg a Release idejét. Ilyenkor a kompresszor lassabban tér vissza az alapállapotába, vagyis hosszabban tartja a jelszint csökkentést, és ezáltal jobban kisimulnak a különbségek. Amikor elkezdjük emelni az értéket, azt tapasztalhatjuk, hogy a hangerő csökkenni kezd, vagyis gyakorlatilag egy lehalkítást hajtunk végre. A feladatunk most az, hogy megtaláljuk azt az ideális értéket, amikor már elegendő hangerő csökkentés történik, de még nem túl hosszan, így megtartva az eredeti dinamikát. Ha túl nagy értéket választunk, akkor nem történik valódi jelszint követés, ha túl alacsonyat, akkor nagy marad a különbség a hangos és halk részek között. Erre legjobb példa az Attack beállításánál is említett "két tűz között MERRE MENJEK ÉN" rész. Számomra a második vonással megegyező érték adja a legkiegyensúlyozottabb hangzást. (lásd a fenti képen) Persze ez ízléstől is függ, másoknak lehet hogy más Attack és Release beállítás tetszik jobban.
Ötödik lépés: Ratio Beállítása. A fenti értékekkel már egy egészen jó énekünk lett, az egyetlen probléma amit érzek, hogy kicsit tompának, fojtottnak és háttérben lévőnek hallom. Mivel az attack beállítása már "tökéletesítve" lett, ezért valami más megoldás után kell néznünk. Oh! Hát a Ratio maximumon van! Bár csak a Range 0 értékét tudom pontosan -ez 1:1 arány-, de sejtésem szerint a 100 közel lehet a 8:1 vagy 10:1-hez. Ez bizony már elég nagy kompresszió, jó lesz csökkenteni. A ThrillseekerLA-n a Range poti felel meg a Ratio-nak, ezért most ezt kell használnunk. Kezdjük hát letekerni 100-tól indulva és figyeljük a hatást! A hangzás sokkal nyitottabb, tisztább lesz, az SZ hangok szépen kezdenek előjönni. Keressünk hát egy számunkra tetsző beállítást, olyat amikor már megvan a kellő kompresszió -vagyis dinamika tartomány csökkentés-, nincsenek túlságosan kiugró hangos vagy halk hangok, de nem is tompul, szűkül még be a hangzás. Szerintem ez az 50% utáni jobbra eső első hosszú vonalnál tapasztalható.

Gyakorlatilag végeztünk az 5 lépéssel, és kaptunk is egy átlagosan kiegyenlített éneket. Viszont ahogy már az előző részben megtanultuk, az egyes paraméterek mindig hatással vannak egymásra, pl. az attack és release beállítása után kompenzálnunk kell a létrejövő GR értéket. Ha rátekintünk a műszerünkre láthatjuk is, hogy az eredetileg beállított -6dB-ből már csak 4 maradt. Ezt emeljük vissza 6-ra az Input potival és kompenzáljuk a jelszint csökkentést az Output-al. A végső beállítást a fenti képen láthatjuk, a létrehozott hullámformával együtt. A ThrillseekerLA-nak köszönhetően a dinamika tartományt sikerült -10 és -12 dBVU közé csökkentenünk úgy, hogy az ének nem veszített sokat eredeti előadásmódjából.
Figyeljük meg, hogy mennyire kiugrik az ének síkjából a "FARKASOK vagy angyalok" rész (9.1.00 13.241 sec) a kompresszor nélkül, és a kompresszorral mennyire belesimul a környezetébe. Bár az MJUC-hoz viszonyítva a hang egy picit tompább (ami EQ-val, vagy akár a beépített szaturációval is kompenzálható), az ott tapasztalt túlzott halkítás (lyuk a hangerőben) a "Merre menjek én" sornál szinte teljesen megszűnt.
 El kell hogy áruljam, hogy egy kicsit csaltam az értékek megtalálásakor, ugyanis -mint ahogy azt már a szemfülesebb olvasók bizonyára észrevették a képeken látható preset nevéből- ezeket egy Waves CLA-2A kompresszorhoz igazítva értem el.
El kell hogy áruljam, hogy egy kicsit csaltam az értékek megtalálásakor, ugyanis -mint ahogy azt már a szemfülesebb olvasók bizonyára észrevették a képeken látható preset nevéből- ezeket egy Waves CLA-2A kompresszorhoz igazítva értem el.
Hogyan tudunk két különböző plugint azonos hangzásra beállítani?
Ha a két sávot fordított polaritással egy mono sávra küldjük, akkor az azonos jelek kioltják egymást. Vagyis addig kell a paramétereket állítgatni, amíg nem hallunk semmit, vagy csak nagyon halkan. Egy másik lehetséges módszer, ha a két mono sávot sztereóban balra és jobbra panorámázzuk. Ezzel a technikával a két oldalon azonnal hallhatóvá válinak a különbségek, középen pedig az azonosságok. Ha csak egyetlen mono hangot hallunk a fantom-középről, akkor szinte biztosak lehetünk benne, hogy a két oldalon pontosan ugyan az szól! Én mindkét technikát alkalmazva kerestem meg a ThrillseekerLA-n a megfelelő beállításokat, ezért is állítom azt, hogy közel 90%-ban azonos az elért kompresszió, mint egy CLA-2A-n. Sajnos azonban egy egy beállítás csak az adott hanghoz alkalmazható, így egy másik éneksáv esetében más beállítások adják az azonos kompressziót. A két plugin tehát csak az eredményben azonos, annak előállítását más módon érik el.

Kapcsoljuk hát ki az MJUC-t és a következő insert pontra helyezzük el a ThrillseekerLA-t. (Ne feledjük a Sleepy Mono Channelt utána helyezni!) Mivel ezen a kompresszoron az általános paraméterek mind megtalálhatóak, a beállítást végezzük most az előző részben megismert 5 lépéses módszer szerint.
Az első lépés a kompresszor alaphelyzetbe állítása. Mivel ez a plugin nem jelzi az aktuális értékeket, így a beállításokat a mellékelt képekről kell majd lemásolni. Fentebb látható az első, a kezdeti értékekkel. Ahogy a nagykönyvben meg van írva, Input 0dB, Attack és Release a lehető legkisebb, Range (ez gyakorlatilag a Ratio-nak felel meg) maximumon, Output 0dB.
Második lépés a Threshold beállítása, igen ám, de itt nincs ilyen. Vagyis nem látjuk sehol sem. Valójában ez a kompresszor rögzített küszöbértékkel dolgozik, és az Input potival tudjuk a beérkező jelet ehhez növelni, vagy csökkenteni. Indítsuk el a lejátszást, és nézzük, mi történik a 0dB-es értéken!
Már a sáv leghalkabb részén is -3dB GR-t jelez a műszerünk, a legmagasabb érték pedig -10dB. A hangja végülis nem rossz, akár meg is felelhetne, ha nem tudnánk hogy a folyamatos -3dB jelszint csökkentésnek nem sok értelme van. Mit tehetünk? Kövessük az eddigi módszerünket, vagyis próbáljuk meg elérni, hogy a halk részeken ne történjen jelszint csökkentés. Ehhez a küszöbértéket kell növelni, azaz halkítsuk le a bemenő jelet az Input-al egészen addig, amíg a leghalkabb részeken már nem lesz GR. Ez kb. 10 óra állásban következik be. Mint hallhatjuk, a halkítással a kimenő jelszint is csökkent, de ezt az Output potival tudjuk kompenzálni. Én nagyjából 2 óra állásnál megfelelőnek találom. Hallgassuk most végig a sávot, hogy mit tesz vele a ThrillseekerLA. Hát nem sokat, a maximális GR -1dB körüli, a Sleepy VU szinte ugyan úgy kileng, mint a kompresszálatlan hang esetében. Ez bizony nem lesz jó megoldás, ismét oda érkeztünk, ahová az MJUC esetében.

Ehhez loopoljuk be a legnagyobb dinamikával rendelkező szakaszt, mégpedig 9.1.0-tól 13.1.0-ig (13.241-19.862sec), biztos ami biztos, halkítsuk le a kimenetet az Output-al mondjuk az alap 0dB-re és indítsuk el a lejátszást. Növeljük az Input-ot addig, amíg a kívánt GR-t el nem érjük. Ez kb. 11 óra körüli állásnál valósul meg. Hallgassuk meg a teljes sávot, és figyeljük a Sleepy VU-t! Még mindig elég nagy a különbség a halk és hangos részek között -10 és -2dB között ingadozik. Sajnos a kompressziós arányt már nem tudjuk tovább növelni, hiszen az maximumon van (Range 100), tehát nem tehetünk mást, mint az Inputot tovább növeljük, mondjuk -6dB GR környékére. Ez bizony a 0dB Input-al lesz a legjobb... Bizony, van amikor az ember téved, de ez nem probléma! A lényeg, hogy a végeredmény jó legyen, ezért ha nem vagyunk biztosak a dolgunkban, inkább próbáljunk ki több lehetőséget is! A 0dB Input-al a leghangosabb résznél -7dB fölé is felmegy a jelszint csökkentés, de semmi baj, jöjjön a következő pont az 5-ből.
Harmadik lépés: Attack beállítása. Ismét jelentkezik az MJUC-nál már tapasztalt pumpáló hatás a "két tűz között MERRE MENJEK ÉN" résznél. Mint ott, itt is az időállandókat kell kezelésbe vennünk. Mivel mi most a lehető leggyorsabb beállításon vagyunk, ezért itt nem működik a még gyorsabbra kapcsolás, de nem is kell! Ha figyelmesek voltunk, már minden bizonnyal észrevettük, hogy az Attack legkisebb értéke 0 ms. Ez bizony túl alacsony érték, a kompresszor ezért nem tud szinte soha visszatérni az alap 0dB GR állapotába. Kezdjük hát ezt növelni, és figyeljük a hatást! Természetesen a problémás részt végtelenítve végezzük a beállítást, 9.1.0 és 13.1.0 között. Ahogy növeljük az Attack értékét, úgy lesz egyre tisztább, nyitottabb a hangzás, és ezzel együtt csökken a GR, valamint a zavaró lehalkulás is. Talán a 7-ik vonásnál a legjobb a beállítás. (lásd a lenti képen)
Ha az értékét visszaszámoljuk a 9-ik vonás 13ms értékéből, akkor kb. 10ms-ot kapunk, ami pont megegyezik az eredeti LA-2A attack idejével, sőt az előző részben ajánlott, legkevésbé észrevehető kompresszióhoz szükséges értékkel is. (Ne feledkezzünk el a jelszint kezelésről, és minden beállítás után korrigáljuk a kimenő jelszintet az eredeti szinthez!)
Ötödik lépés: Ratio Beállítása. A fenti értékekkel már egy egészen jó énekünk lett, az egyetlen probléma amit érzek, hogy kicsit tompának, fojtottnak és háttérben lévőnek hallom. Mivel az attack beállítása már "tökéletesítve" lett, ezért valami más megoldás után kell néznünk. Oh! Hát a Ratio maximumon van! Bár csak a Range 0 értékét tudom pontosan -ez 1:1 arány-, de sejtésem szerint a 100 közel lehet a 8:1 vagy 10:1-hez. Ez bizony már elég nagy kompresszió, jó lesz csökkenteni. A ThrillseekerLA-n a Range poti felel meg a Ratio-nak, ezért most ezt kell használnunk. Kezdjük hát letekerni 100-tól indulva és figyeljük a hatást! A hangzás sokkal nyitottabb, tisztább lesz, az SZ hangok szépen kezdenek előjönni. Keressünk hát egy számunkra tetsző beállítást, olyat amikor már megvan a kellő kompresszió -vagyis dinamika tartomány csökkentés-, nincsenek túlságosan kiugró hangos vagy halk hangok, de nem is tompul, szűkül még be a hangzás. Szerintem ez az 50% utáni jobbra eső első hosszú vonalnál tapasztalható.

Gyakorlatilag végeztünk az 5 lépéssel, és kaptunk is egy átlagosan kiegyenlített éneket. Viszont ahogy már az előző részben megtanultuk, az egyes paraméterek mindig hatással vannak egymásra, pl. az attack és release beállítása után kompenzálnunk kell a létrejövő GR értéket. Ha rátekintünk a műszerünkre láthatjuk is, hogy az eredetileg beállított -6dB-ből már csak 4 maradt. Ezt emeljük vissza 6-ra az Input potival és kompenzáljuk a jelszint csökkentést az Output-al. A végső beállítást a fenti képen láthatjuk, a létrehozott hullámformával együtt. A ThrillseekerLA-nak köszönhetően a dinamika tartományt sikerült -10 és -12 dBVU közé csökkentenünk úgy, hogy az ének nem veszített sokat eredeti előadásmódjából.
Figyeljük meg, hogy mennyire kiugrik az ének síkjából a "FARKASOK vagy angyalok" rész (9.1.00 13.241 sec) a kompresszor nélkül, és a kompresszorral mennyire belesimul a környezetébe. Bár az MJUC-hoz viszonyítva a hang egy picit tompább (ami EQ-val, vagy akár a beépített szaturációval is kompenzálható), az ott tapasztalt túlzott halkítás (lyuk a hangerőben) a "Merre menjek én" sornál szinte teljesen megszűnt.

Hogyan tudunk két különböző plugint azonos hangzásra beállítani?
Ha a két sávot fordított polaritással egy mono sávra küldjük, akkor az azonos jelek kioltják egymást. Vagyis addig kell a paramétereket állítgatni, amíg nem hallunk semmit, vagy csak nagyon halkan. Egy másik lehetséges módszer, ha a két mono sávot sztereóban balra és jobbra panorámázzuk. Ezzel a technikával a két oldalon azonnal hallhatóvá válinak a különbségek, középen pedig az azonosságok. Ha csak egyetlen mono hangot hallunk a fantom-középről, akkor szinte biztosak lehetünk benne, hogy a két oldalon pontosan ugyan az szól! Én mindkét technikát alkalmazva kerestem meg a ThrillseekerLA-n a megfelelő beállításokat, ezért is állítom azt, hogy közel 90%-ban azonos az elért kompresszió, mint egy CLA-2A-n. Sajnos azonban egy egy beállítás csak az adott hanghoz alkalmazható, így egy másik éneksáv esetében más beállítások adják az azonos kompressziót. A két plugin tehát csak az eredményben azonos, annak előállítását más módon érik el.

Optron 3A (LA-3A)
Az eredeti LA-3A az LA-2A továbbfejlesztett, modernizált változata, ami már nem elektroncsöves, hanem tranzisztoros erősítővel, de ugyan azzal a T4-es opto-elektronikus detektorral rendelkezik. Az eredeti LA-2A attack ideje 10ms, a release 60ms 50%-ig, majd 500-5000ms a teljes alaphelyzetig. Az LA-3A attack-ja viszont csak 1,5ms vagy kevesebb, release ideje pedig 60ms 50% GR-ig. Látható tehát, hogy "gyorsabb" mint az elődje.
Mindezt hallhatjuk az ingyenes Phoenixinflight-Optron 3A-nál is, ami nem meglepő módon az LA-3A "másolata". Ennek a gyorsabb reagálásnak köszönhetően sokkal jobban követi a jelszint változásokat. Mint ahogy a képen is láthatjuk, sajnos a pluginben lévő GR mérő műszer kalibrálása hagy némi kívánnivalót maga után, ezért beállításkor a leolvasható értékekkel ne törődjünk, figyeljük inkább csak a mozgását. Ha csak a hallásunkra hagyatkozunk, egy jó kompressziót tudunk beállítani.
Tájékoztatásképpen elmondom, hogy kb. milyen értékekkel számolhatunk az Optron GR mérőjén, 1000Hz szinusz hullámmal mérve:
Optron: -1dB, -2dB, -3dB, -6dB
Valós: -3dB, -6dB, -9dB, kb. -15dB

Tapasztalatom szerint az Optron közel azonos hangzást produkál, mint a ThrillseekerLA, de csak fele akkora CPU igénye van. Kár, hogy a VU metere nem megfelelő értékeket mutat, mert egyébként ez egy jó ingyenes kompresszor lenne!
VCA kompresszor
Bár a VCA kompresszorok tulajdonképpen mindenesnek tekinthetőek, elsősorban inkább busz kompresszorként terjedtek el, ami leginkább a gyorsaságuknak és tiszta hangzásuknak köszönhető. Ez alól kivétel talán a dbx 160 sorozata, amit viszont előszeretettel használnak dobokon és basszuson is. Mivel mi most nem a hangzást szeretnénk megváltoztatni, hanem a szinteket kiegyenlíteni, ezért a gyors reakció nem feltétlenül fontos. Amiért mégis érdemes a VCA kompresszorokat szintező erősítőként is alkalmazni, az az automatikus Attack és Release lehetősége. A sorozat 6-ik részében már megismertük a dlm SIXTYFIVE plugint és használatát, ezért erre itt most nem térek ki részletesen. Aki nem ismeri, tanulmányozza át az ott leírtakat. Ez a plugin rendelkezik auto attack és release opcióval, kapcsoljuk hát be és teszteljük hogy mit tud az éneksávunkon!
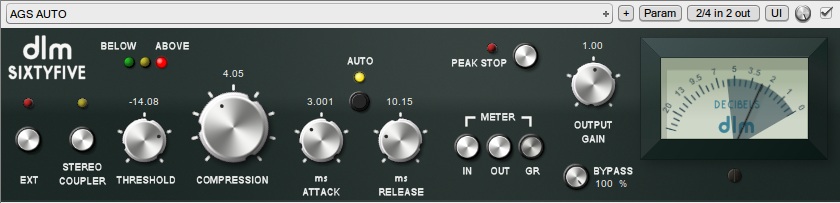
A beállításkor nem lesz nehéz dolgunk, mindössze a szükséges Threshold és Compression értékekkel kell foglalkoznunk, ezekkel kell elérni egy -5-6dB-es GR-t, a többit az Auto Attack és Release elintézi helyettünk!
A beállítást természetesen a Threshold-al kezdjük, igyekezzünk olyan értéket választani, hogy a halk részeken a zöld, vagy a sárga LED világítson, és a piros csak a hangosabbaknál. Ugye hogy milyen okos ötlet volt ezt a 3 ledet beépíteni? Ha megvan a megfelelő küszöbérték (nálam -14dB), akkor már csak a Compression-el be kell állítanunk a kívánt GR-t. Ebben a pluginben a Compression felel meg a Ratio-nak, a feltüntetett értékek pedig az arányt jelentik. Vagyis a 4-es Compression azt jelenti, 4:1 arányú kompresszió. Mivel az eredeti LA-2A is többé kevésbé itt dolgozik, válasszuk most ezt! Meg is jön a várt -6dB GR érték. Meglepően szépen dolgozik a plugin, egy kis hibától eltekintve jól és pontosan követi a hangerő változásokat, tisztán és érthetően szól. (Használjuk a fenti képen látható beállításokat.) Auto módban a SIXTYFIVE -10 és -3dB közé szorította be a dinamikatartományt, ami azért nem semmi!
Ha észrevettük a hibát az AUTO módban és zavar minket, akkor nincs más választásunk, mint manuálisan megadni az Attack és Release értékeit. Kapcsoljuk ki az AUTO módot és kezdjük 5ms Attack-al és 100ms Relase-el. Hallgassuk meg a sávot, és keressük meg a problémás részeket. Szerintem ez leginkább 11.1.0 és 13.1.0 között lévő "merre menjek én" rész. Itt bizony hallhatóan lehalkul az énekünk, pedig nem kéne.
Csökkentsük az Attack-ot 1ms-ra. Sokkal rosszabb lett, sőt már a "farkasok"-nál is hallatszik a kéretlen halkulás. Tehát nem csökkenteni, hanem növelni kell az Attack-ot. Haladjunk felfelé most 5ms-onként. 5-el kezdtük a keresést, az ugye nem volt jó, jöjjön most a 10ms. Már jobb, de még mindig nem az igazi, a "merre menjek én" még mindig elfojtódik. Jöjjön a 15ms. Még mindig halkul, jöjjön a 20ms, hát ez sem jó.
 Itt bizony valami más lesz a gond... Nézzük a Sleepy VU meter mozgását. Nem a "menjek én" a halk, hanem a "merre" túl hangos. Vagyis nem kerül elegendő jelszint csökkentés alá. Vajon miért? Lehet hogy túl hosszú az Attack időnk, és ez a viszonylag rövid és erős jelcsúcs átjut csökkentetlenül? Menjünk vissza egy gyorsabb Attackra, mondjuk 5ms-ra és hallgassuk meg újból a kérdéses részt. A "menjek én"-nél a GR mérő még emelkedik, ami azt jelenti, hogy a kompresszor Attack fázisban van, tehát növeli a GR értékét, ezért halkul le ez a rész. Csökkentsük a Release értéket, hogy a detektor gyorsabban tudja a Release fázisba lépve megkezdeni a visszatérést a GR csökkentéséhez. 50ms-nál már hallható egy kis javulás, de 10ms Release-nél már szinte tökéletes.
Itt bizony valami más lesz a gond... Nézzük a Sleepy VU meter mozgását. Nem a "menjek én" a halk, hanem a "merre" túl hangos. Vagyis nem kerül elegendő jelszint csökkentés alá. Vajon miért? Lehet hogy túl hosszú az Attack időnk, és ez a viszonylag rövid és erős jelcsúcs átjut csökkentetlenül? Menjünk vissza egy gyorsabb Attackra, mondjuk 5ms-ra és hallgassuk meg újból a kérdéses részt. A "menjek én"-nél a GR mérő még emelkedik, ami azt jelenti, hogy a kompresszor Attack fázisban van, tehát növeli a GR értékét, ezért halkul le ez a rész. Csökkentsük a Release értéket, hogy a detektor gyorsabban tudja a Release fázisba lépve megkezdeni a visszatérést a GR csökkentéséhez. 50ms-nál már hallható egy kis javulás, de 10ms Release-nél már szinte tökéletes.
A "merre" szó még mindig túlzottan hangos, kiemelkedik a többi közül, nagyobb jelszintcsökkentésre van szüksége. Próbáljuk ki mi lesz, ha csökkentünk egy kicsit az Attack értékén, mivel így sokkal gyorsabban éri el a kompresszor a szükséges GR értéket, vagyis hamarabb fogja lehalkítani az adott szót. Mint mindig, most is próbáljunk meg egy közép értéket 0 és 5ms között, ez ugye 2,5ms. Szerintem kicsit sok, nagyon hallható a jelszint csökkentés, emeljünk egy kicsit, mondjuk 3ms-ra. Szerintem sokkal jobb, tulajdonképpen nekem így jó is! Meglepő, hogy ilyen apró eltérés már ekkora különbséget jelent a hangzásban, de ez most jó lecke volt ahhoz, hogy legközelebb ezt már ne felejtsük el!

Természetesen az új időállandókkal a GR értéke is megváltozott, amit most kompenzálnunk kell a -6dB körüli jelszint csökkentéshez, ezért a Threshold -17, a Compression pedig 6.1-re változik. Ezeket a végső értékeket láthatjuk a fenti képen is, a létrehozott hullámformával együtt. Ne feledjük a gain staging-et, és kompenzáljuk a kimeneti jelszintet is 0,4dB-re!
Ha most visszakapcsoljuk az AUTO módot, hallhatjuk, hogy óriási a különbség, a manuális beállítás sokkal tisztább, kevésbé zavaró kompressziót biztosít. Látható tehát, hogy bár az auto mód sokszor nagyon intelligens, a nehezebb esetekben szükséges lehet a kézi beállítás.
A beállítást természetesen a Threshold-al kezdjük, igyekezzünk olyan értéket választani, hogy a halk részeken a zöld, vagy a sárga LED világítson, és a piros csak a hangosabbaknál. Ugye hogy milyen okos ötlet volt ezt a 3 ledet beépíteni? Ha megvan a megfelelő küszöbérték (nálam -14dB), akkor már csak a Compression-el be kell állítanunk a kívánt GR-t. Ebben a pluginben a Compression felel meg a Ratio-nak, a feltüntetett értékek pedig az arányt jelentik. Vagyis a 4-es Compression azt jelenti, 4:1 arányú kompresszió. Mivel az eredeti LA-2A is többé kevésbé itt dolgozik, válasszuk most ezt! Meg is jön a várt -6dB GR érték. Meglepően szépen dolgozik a plugin, egy kis hibától eltekintve jól és pontosan követi a hangerő változásokat, tisztán és érthetően szól. (Használjuk a fenti képen látható beállításokat.) Auto módban a SIXTYFIVE -10 és -3dB közé szorította be a dinamikatartományt, ami azért nem semmi!
 |
| Manuális mód kezdeti értékei |
Csökkentsük az Attack-ot 1ms-ra. Sokkal rosszabb lett, sőt már a "farkasok"-nál is hallatszik a kéretlen halkulás. Tehát nem csökkenteni, hanem növelni kell az Attack-ot. Haladjunk felfelé most 5ms-onként. 5-el kezdtük a keresést, az ugye nem volt jó, jöjjön most a 10ms. Már jobb, de még mindig nem az igazi, a "merre menjek én" még mindig elfojtódik. Jöjjön a 15ms. Még mindig halkul, jöjjön a 20ms, hát ez sem jó.
A "merre" szó még mindig túlzottan hangos, kiemelkedik a többi közül, nagyobb jelszintcsökkentésre van szüksége. Próbáljuk ki mi lesz, ha csökkentünk egy kicsit az Attack értékén, mivel így sokkal gyorsabban éri el a kompresszor a szükséges GR értéket, vagyis hamarabb fogja lehalkítani az adott szót. Mint mindig, most is próbáljunk meg egy közép értéket 0 és 5ms között, ez ugye 2,5ms. Szerintem kicsit sok, nagyon hallható a jelszint csökkentés, emeljünk egy kicsit, mondjuk 3ms-ra. Szerintem sokkal jobb, tulajdonképpen nekem így jó is! Meglepő, hogy ilyen apró eltérés már ekkora különbséget jelent a hangzásban, de ez most jó lecke volt ahhoz, hogy legközelebb ezt már ne felejtsük el!

Természetesen az új időállandókkal a GR értéke is megváltozott, amit most kompenzálnunk kell a -6dB körüli jelszint csökkentéshez, ezért a Threshold -17, a Compression pedig 6.1-re változik. Ezeket a végső értékeket láthatjuk a fenti képen is, a létrehozott hullámformával együtt. Ne feledjük a gain staging-et, és kompenzáljuk a kimeneti jelszintet is 0,4dB-re!
Ha most visszakapcsoljuk az AUTO módot, hallhatjuk, hogy óriási a különbség, a manuális beállítás sokkal tisztább, kevésbé zavaró kompressziót biztosít. Látható tehát, hogy bár az auto mód sokszor nagyon intelligens, a nehezebb esetekben szükséges lehet a kézi beállítás.
Limiter
Biztosan sokakban felmerült már a kérdés, hogy ha az a cél, hogy egyforma hangerőt érjünk el a teljes sávon belül, akkor miért nem használunk erre a célra limitert? Ha a maszterelésnél megoldható, hogy csak a hangerőt novelje és a hangzást ne változtassa meg, akkor egy egyéni sávon is képes lehet erre és nem kell a sok paramétert állítgatni. Sajnos rossz hírem van, a maszterelésnél is megváltoztatja a hangzást, és bizony ott is inkább kompresszort használnak a hangerő növelésre, nem pedig limitert. Azt inkább csak a túlvezérlés megakadályozására alkalmazzák. Hogy miért, azt máris kipróbáljuk!

Helyezzük el az első szabad insert pontra az ingyenes dlm-Clipstar plugint. Ez egy úgynevezett soft limiter, de mi most inkább a hard limit funkciót fogjuk használni, hogy még látványosabb legyen a létrejövő hangzás! Kapcsoljuk ki az eddigi kompresszorokat és állítsuk be a Clipstar-t a képen látható módon. Indítsuk el a lejátszát és máris hallhatjuk az elrettentő példát, vagyis a torzítást. Bár az előállított wav képe nagyon szép egységes hangerőt sejtet, szerintem senki sem szeretné ha az éneksávja így szólna... A hangerő nagyjából megegyezik a többi kompresszoréval, viszont ehhez közel -20dB-es GR tartozik. Ha lejátszás közben megfigyeljük a Sleepy VU metert, meglepődve láthatjuk, hogy a torz hang ellenére is bizony igen nagy maradt a dinamika tartomány, -15 és néha 0dBVU között helyezkedik el. Ha a Soft Limit-et is elkezdjük növelni, egy valódi torzítót fogunk hallani, érdemes kipróbálni!

Helyezzük el az első szabad insert pontra az ingyenes dlm-Clipstar plugint. Ez egy úgynevezett soft limiter, de mi most inkább a hard limit funkciót fogjuk használni, hogy még látványosabb legyen a létrejövő hangzás! Kapcsoljuk ki az eddigi kompresszorokat és állítsuk be a Clipstar-t a képen látható módon. Indítsuk el a lejátszát és máris hallhatjuk az elrettentő példát, vagyis a torzítást. Bár az előállított wav képe nagyon szép egységes hangerőt sejtet, szerintem senki sem szeretné ha az éneksávja így szólna... A hangerő nagyjából megegyezik a többi kompresszoréval, viszont ehhez közel -20dB-es GR tartozik. Ha lejátszás közben megfigyeljük a Sleepy VU metert, meglepődve láthatjuk, hogy a torz hang ellenére is bizony igen nagy maradt a dinamika tartomány, -15 és néha 0dBVU között helyezkedik el. Ha a Soft Limit-et is elkezdjük növelni, egy valódi torzítót fogunk hallani, érdemes kipróbálni!
Darabolás, kézi kiegyenlítés
Láthatjuk, hogy a fenti kompresszorokkal elég jól ki tudtuk egyenlíteni az éneksávunkon található hangerő különbségeket, de mivel túl nagy a dinamika különbség az egyes szavak és sorok között, ezért egyik kompresszor sem volt teljesen tökéletes. Ehhez a legjobb megoldás a kézzel történő fader automatizáció. Ha mégsem ezt választjuk, hanem maradunk a kompresszornál, akkor viszont könnyítsük meg a dolgát egy kis előkezeléssel. Ezt többféle módon is megtehetjük.
Az egyik lehetséges megoldás, hogy két kompresszort használunk sorba kötve. Az elsőn egy gyors attack és gyors release, valamint magas küszöbértékkel csak a rövid idejű, erős jelcsúcsokat csökkentjük. Az így kialakult "simább", kisebb dinamikatartományú jelet küldjük azután a második kompresszorba, ami a fentiekben már ismertetett szintező erősítő szerepét tölti be.

Ha nem vagyunk túlságosan lusták, akkor kerülhet szóba a második megoldás. Ebben az első kompresszor szerepét mi magunk vesszük át. A túlságosan eltérő hangosságú részeket szeleteljük, majd kézzel külön-külön beállítjuk a hangerejüket. A legtöbb DAW lehetővé teszi, hogy az egyes audió elemek hangerejét egyesével adjuk meg. Ez már majdnem fader automatizáció, de annál sokkal gyorsabban elkészül, viszont sokkal kevésbé pontos. Tulajdonképpen ilyenkor csak egy nagyolást végzünk, a finom kiegyenlítést ugyan úgy egy szintező erősítőre bízzuk. Az egyes hangerők beállításánál használjuk a kivezérlés mérőt, vagy bízzunk meg a hallásunkban. Egészen addig próbálgassuk a különböző értékeket, amíg nagyjából egyforma hangerőt nem kapunk a teljes sáv alatt.
A fenti kép felső részén láthatjuk a felszeletelt éneksávot, alul pedig az eredetit. A szeleteken és az eredetin is látható egy fekete vízszintes vonal, ez jelzi az adott szelet jelszint beállítását. A pontos érték a szeletek alján számmal is megjelenik. Látható, hogy vannak különbségek, tehát mindenképpen érdemes ezt a módszert alkalmazni a kompresszor működésének megkönnyítésére ha jó minőségű mixet szeretnénk készíteni!
Ne feledjük hogy mindazt amit ma tanultunk, nem csak ének sávokon, hanem bármilyen hangfelvételen alkalmazhatjuk!
A fenti kép felső részén láthatjuk a felszeletelt éneksávot, alul pedig az eredetit. A szeleteken és az eredetin is látható egy fekete vízszintes vonal, ez jelzi az adott szelet jelszint beállítását. A pontos érték a szeletek alján számmal is megjelenik. Látható, hogy vannak különbségek, tehát mindenképpen érdemes ezt a módszert alkalmazni a kompresszor működésének megkönnyítésére ha jó minőségű mixet szeretnénk készíteni!
Ne feledjük hogy mindazt amit ma tanultunk, nem csak ének sávokon, hanem bármilyen hangfelvételen alkalmazhatjuk!
Ének kompresszió ajánlott kezdeti értékei

Ratio: 2:1 és 5:1 között. Attól függ, hogy menyire szeretnénk kompresszált hangot hallani, ill. hogy milyen a használt eszközünk jelleggörbéje (hard vagy soft-knee). Kezdjük 3:1-el, és onnan növeljük, vagy csökkentsük, attól függően hogy milyen nagy a dinamikatartományunk, mennyire megfelelő a szintkiegyenlítés.
Threshold: Ez is attól függ, hogy mennyire szeretnénk az éneket összenyomni. Ha túl alacsony értéket állítunk be (0dB-hez közeli értékek), akkor csak a rövid jelcsúcsok lesznek csillapítva, ha túl magasat (-∞ dB-hez közeli értékek), nem történik valódi jelszint követés, csak lehalkítás.
Attack: Természetesen az elérni kívánt hatástól, és a tempótól, ritmikától is függ, de általában 1-3ms között érdemes kezdeni. Ha szintezést, vagy transzparens kompressziót szeretnénk, akkor inkább 10ms-ról induljunk.
Release: Szintén a feladathoz kell igazítani! Alapértéknek 250-350ms-al, vagy többel induljunk. Ha pumpáló hatást érzékelünk, csökkentsük az értéket addig, amíg meg nem szűnik. Ha van Auto Relase, használjuk azt!
Make-up: Nyilván a létrejött GR-hez kell igazítani, vagyis végezzük el a gain staging-et.
GR (jelszint csökkentés): általában -3-6dB közötti értékek jöhetnek szóba, kezdetnek alkalmazzunk -4dB-t. Az arcban szóló hanghoz felmehetünk egészen -20dB-ig is!

A témával kapcsolatos kérdéseket és kéréseket várom itt a kommentekben, vagy a Facebook oldalon!
Kellemes mixelést kívánok mindenkinek!
A következő részhez katt ide...
https://www.soundonsound.com/sos/oct09/articles/qa1009_2.htm
https://randycoppinger.com/2013/03/05/voice-how-to-compress/
https://www.soundonsound.com/sos/sep09/articles/classiccompressors.htm
DIY Vocal rider
http://www.soundonsound.com/sos/jun10/articles/cubase_0610.htm
Leveling Amplifier
http://www.uaudio.com/hardware/compressors/la-2a.html
http://www.uaudio.com/la-3a.html
Kedves Cikk Író!
VálaszTörlésEgy olyan kérdésem lenne az éneksáv felvételével kapcsolatban, hogy azt hány dB-vel érdemes vagy ajánlott rögzíteni? Az én legutolsó informáciom az -15 és -20dB közötti érték. Ez nem tudom, hogy mennyire helytálló. Válaszát előre is köszönöm.
Köszönöm ezt a fantasztikus összeállítást én még ilyen részletesen a témával sehol nem találkoztam.
Tisztelettel Társi Norbert
Kedves Norbert!
VálaszTörlésSajnos nem egyértelmű számomra a kérdésed. Ha a felvételi jelszintre gondolsz, akkor én a 0VU-t ajánlom. Ez 24bites digitális rögzítés esetében az európai szabványok szerint -18dBFS-nek felel meg. Ez egy közepes jelszint, tehát a jelcsúcsok nyilván ennél magasabbak lesznek. Ha a DAW peak meterén nézed, akkor ne legyen a leghangosabb jel sem több, mint -6dBFS.
A decibelekről és jelentésükről részletesen olvashatsz ebben a sorozatban:
http://microchips-sound-studio.blogspot.hu/2015/10/minden-decibelekrol-1-resz.html
A felvételi és lejátszási szintekkel kapcsolatban pedig részletesebb információkat ebben a részben találsz:
http://microchips-sound-studio.blogspot.hu/2015/10/minden-decibelekrol-3-resz.html
Üdvözlettel:
AGS
Microchips Sound Studio